
Is RAG the New King of Search? | 매거진에 참여하세요
Is RAG the New King of Search?
#query #search #intention #vector #rag #db #research #ai




How Retrieval-Augmented Generation Is Redefining Information Discovery
For decades, we typed keywords into a search bar and combed through pages of blue links. That was “search.”
But in the wake of GPT-4o, Perplexity, and a wave of RAG (Retrieval-Augmented Generation) powered services,
this entire paradigm is shifting.
We’re moving from “searching” to “assembling.”
And at the heart of this transformation lies a simple question:
What if the engine doesn’t just find information, but understands what you’re really asking — and builds the answer for you?
Goodbye Search, Hello Research
Traditional search engines are built on exact keyword matching and PageRank-style scoring.
This works well when you know exactly what to ask.
But in reality, most of our questions are fuzzy.
When a founder types “tax tips for early-stage startups” into Google,
the result is often a mix of outdated blog posts and irrelevant news.
Why?
Because the search engine doesn't truly understand what you mean. It just finds documents that happen to contain similar words.
Enter RAG.
What Is RAG?
RAG (Retrieval-Augmented Generation) is a method that augments large language models with external knowledge.
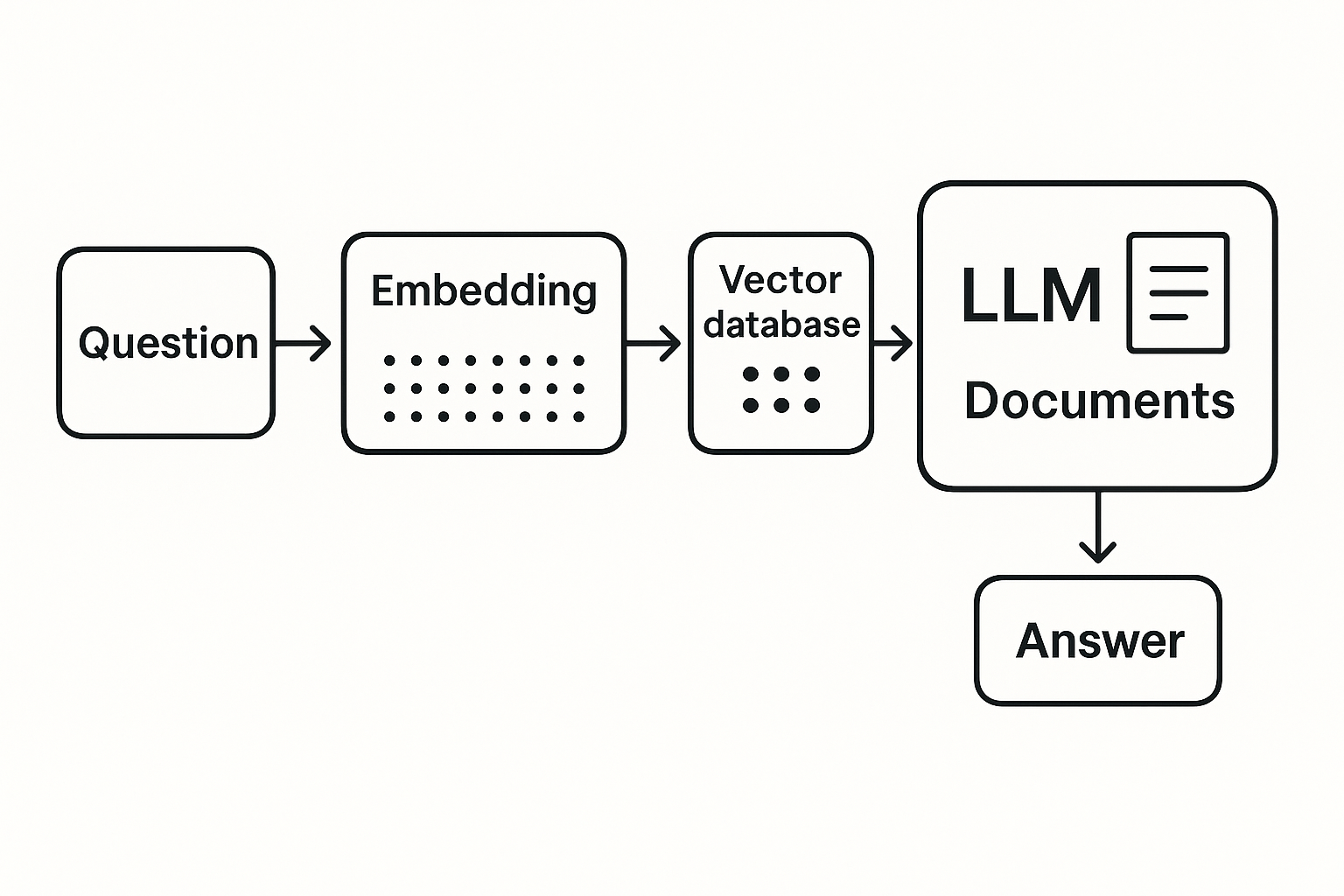
It works like this:
- Your question is transformed into a vector — a position in high-dimensional semantic space.
- That vector is used to retrieve relevant documents from a vector database (like Pinecone or Weaviate).
- The retrieved content is passed into a language model, which generates a coherent, contextual answer.
Instead of generating text from scratch, the model now builds on actual information — like citations, facts, or code snippets.
RAG isn’t a black box that “hallucinates.”
It’s a hybrid system: part search engine, part summarizer, part intelligent assistant.
The Real Star? Vector Databases
Underneath all of this, RAG relies on vector databases.
Unlike traditional databases that compare literal words, vector DBs encode the meaning of a sentence into a high-dimensional vector.
This enables semantic search — the engine retrieves not just what looks similar, but what means something similar.
Here’s a snapshot of the current vector DB landscape:
Product | Highlights | Open Source | Used by |
|---|---|---|---|
Pinecone | Fully managed, optimized for LLMs | ❌ | Notion, Perplexity |
Weaviate | Combines graph & vector search | ✅ | Open-source LLM tools |
Qdrant | Rust-based, blazing fast inference | ✅ | SaaS & embedded apps |
Chroma | Default in LangChain, great for prototyping | ✅ | Side projects |
The key isn’t just in performance — it’s how well you query.
The embedding model, filtering strategy, and interpretation of user intent define the whole UX.
RAG UX Is Not “Search,” It’s Guided Exploration
AI-native search engines like Perplexity, ChatGPT (with browsing), or You.com now provide a fundamentally different experience.
- Perplexity shows source links in-line, building user trust.
- ChatGPT’s web mode condenses dozens of pages into a clean, synthesized summary.
What’s different?
You see what the AI saw
RAG systems transparently cite sources, giving users context.
You get reasoning, not just results
These aren’t links — they’re synthesized answers built on evidence.
You’re guided by purpose, not keywords
RAG interprets your intent, not just your literal words.
RAG Reframes the User Journey
Instead of:
Search → Click → Read → Repeat
The RAG loop is:
Ask → Get summarized insight → Ask again (refine) → Deeper understanding
Search becomes a conversation, not an interface.
You're not scanning documents. You're iterating your way toward clarity.
So… Is RAG the New Search Engine?
Not exactly.
RAG doesn’t replace search. It replaces what we think search is for.
When we search, we’re not looking for websites. We’re looking for understanding.
We want context. Structure. Recommendations. Relevance.
RAG delivers that, directly — and with the backing of real data, not just prediction.
So no, RAG is not the new king of search.
It’s the king of research.
And if you want to experience that shift firsthand?
Try bunzee.ai — an AI research assistant built on RAG.
It doesn’t just find your answer. It helps you build it.

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
